
Why RAG Gives Different Answers Every Time (And How to Fix It)
NLP

This piece breaks down exactly why RAG gives different answers, layer by layer, and walks through the approaches that actually fix it — from quick engineering wins to architectural shifts that eliminate the root cause.
You ask your RAG system the same question twice. You get two different answers. Neither is wrong, exactly — but they're not the same, either. One cites paragraph three of the policy document. The other cites paragraph seven. One says "12 weeks of parental leave." The other says "employees are eligible after one year of tenure." Both are grounded in real source material, but yet appear incomplete, and neither gives you confidence that the system is reliable enough to put in front of a customer, a compliance officer, or an executive team.
It's tempting to view this as a pure hallucination problem, but the team at Siftree has proven this to be more of a consistency problem. This problem can be more dangerous than hallucination as well because the outputs look trustworthy — they just shift depending on which chunks the retriever happened to surface, how the embeddings aligned on that particular run, and what the language model decided to emphasize during generation.
If you're building production AI systems that touch real decisions — customer support, market intelligence, financial analysis, regulatory compliance — this inconsistency is the wall you will eventually hit.
This piece breaks down exactly why it happens, layer by layer, and walks through the approaches that actually fix it — from quick engineering wins to architectural shifts that eliminate the root cause.
The Anatomy of RAG Inconsistency
RAG (Retrieval-Augmented Generation) is a deceptively simple architecture: take a user query, retrieve relevant documents from a knowledge base, and feed those documents as context to a language model that generates an answer. The idea is sound but the execution is where things fracture.
Inconsistency in RAG doesn't come from a single point of failure, rather, it emerges from compounding variance across three layers: retrieval, context assembly, and generation. Each layer introduces its own sources of non-determinism, and because they're stacked, small fluctuations at the retrieval layer can cascade into dramatically different outputs at the generation layer.
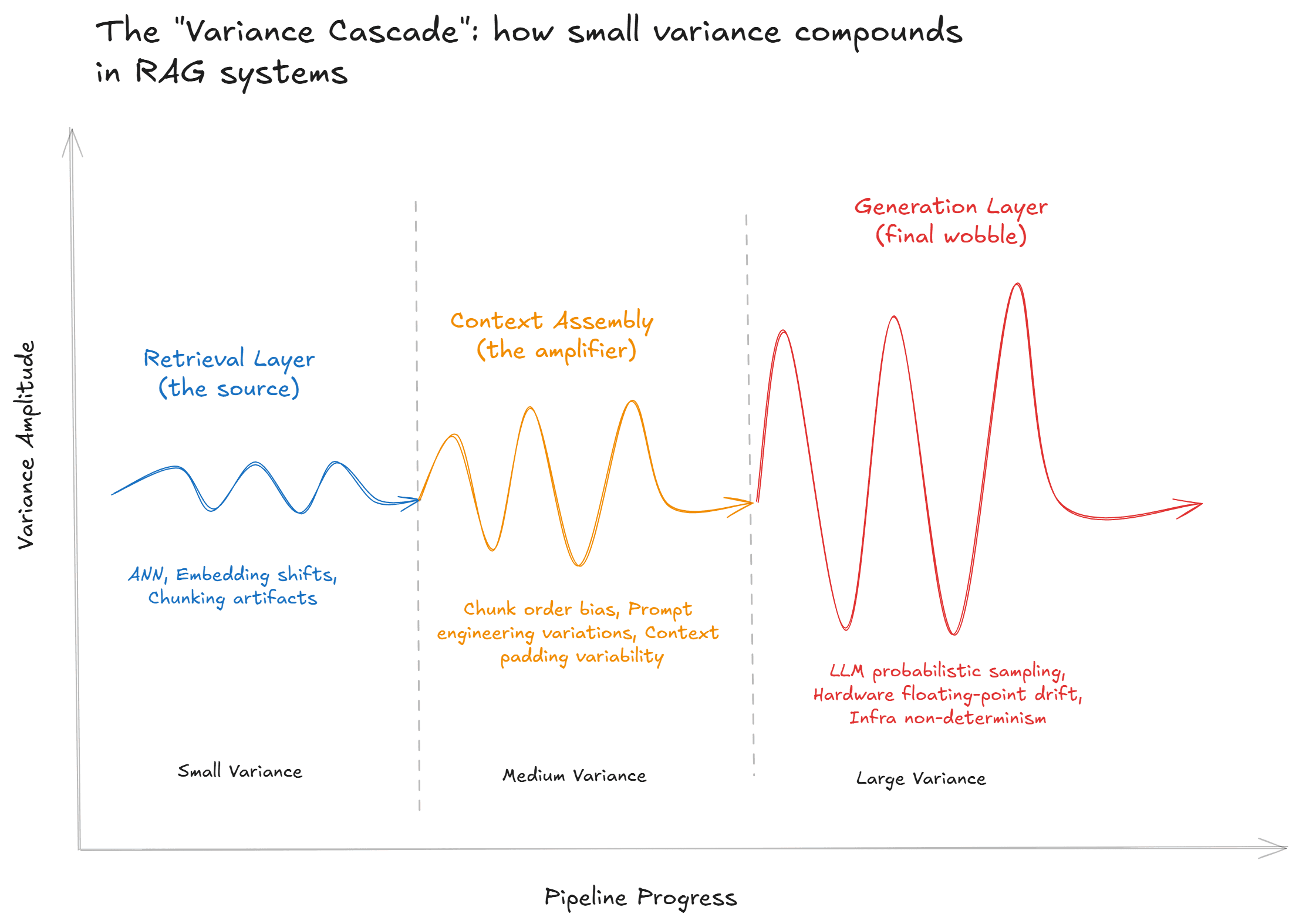
Layer 1: Retrieval Variance
The retrieval layer is where most inconsistency originates. In a standard vector-based RAG pipeline, documents are split into chunks, embedded into high-dimensional vectors, and stored in a vector database. When a query comes in, it's also embedded, and the system retrieves the top-k chunks by cosine similarity.
Although this sounds deterministic it often isn't.
Chunking artifacts. How you split documents determines what the retriever can find. A fixed-size chunking strategy might slice a table in half, split a key paragraph across two chunks, or separate a conclusion from the evidence that supports it. The retriever then surfaces incomplete fragments, and the model fills in the gaps — differently each time.
Approximate nearest neighbor (ANN) search. Most production vector databases don't perform exact similarity search. They use approximate algorithms (HNSW, IVFFlat, etc.) that trade precision for speed. These algorithms can return slightly different result sets depending on index state, load balancing, concurrent queries, and internal partitioning. The result: identical queries, different retrieved chunks.
Embedding instability. Embedding models map semantically similar text to nearby points in vector space, but "nearby" is relative. Two phrasings of the same question can land in slightly different neighborhoods, pulling back overlapping but non-identical document sets. The more ambiguous the query, the wider the variance.
Latency-bounded retrieval. Some vector databases implement timeout guards that return partial results under load. If your system is handling concurrent requests, the same query might get a full result set at 2 AM and a truncated one at 2 PM.
The net effect: your retriever is not a stable function that can take in the same input and produce a variable output. Everything downstream inherits this variance.
Layer 2: Context Assembly
Once chunks are retrieved, they need to be assembled into the prompt that gets sent to the language model. This step introduces its own sources of drift.
Chunk ordering. The order in which retrieved chunks appear in the context window affects how the model weighs them. Language models exhibit well-documented primacy and recency bias — information at the beginning and end of the context window gets disproportionate attention (similar to the human brain!). If your retriever returns the same chunks in a different order (which ANN search can easily produce), the model will emphasize different facts.
Context window overflow. When the total retrieved text exceeds the model's context window, something has to be cut. Most pipelines truncate or re-rank (run another similarity scoring methodology to prune the final results). Both introduce non-determinism: truncation depends on chunk order (which is already variable), and re-ranking models can themselves be non-deterministic.
Metadata leakage. If your pipeline includes metadata (timestamps, source labels, document titles) in the prompt, variations in how that metadata is formatted or ordered can subtly steer the model's interpretation.
Layer 3: Generation Variance
Even with identical context, language models are probabilistic; they generate output by sampling from a probability distribution over the next token. Temperature, top-p, and top-k settings control how much randomness is introduced, but even at temperature=0, perfect determinism isn't guaranteed. Why is that?
GPU floating-point arithmetic is non-deterministic in many frameworks.
Prompt caching mechanisms can alter behavior between the first and subsequent runs.
And backend infrastructure changes (model updates, load balancing across GPU clusters) introduce invisible drift.
These generation-level effects are well-understood and relatively manageable in isolation, but the real problem is that they compound the retrieval and context variance. A slightly different set of retrieved chunks leads to a meaningfully different prompt, which leads to a substantially different answer — and the system gives you no signal or traceable message that any of this happened!
Why Temperature Tuning and Prompt Engineering Aren't Enough
The first instinct when confronting RAG inconsistency is to reach for the generation knobs: set temperature to zero, fix the random seed, constrain the output format. These are reasonable steps but are not sufficient.
Setting temperature to zero reduces generation-layer variance but does nothing about retrieval variance. If the retriever returns different chunks, the model will generate different answers even with fully deterministic decoding. You've tightened one source of noise while the dominant source remains unconstrained.
Prompt engineering — adding explicit instructions like "only answer from the provided context" or "if the context is insufficient, say so" — improves faithfulness but doesn't address the fundamental issue that the context itself is unstable. The model follows instructions faithfully and does it with respect to whichever chunks happened to show up.
These are surface-level mitigations that only reduce symptom severity without treating the underlying condition.
Approach 1: Better Retrieval Hygiene
Before rethinking your architecture, there are real gains to be had from tightening your retrieval pipeline.
Semantic Chunking
Replace fixed-size chunking with strategies that respect document structure. Sentence-level splitting, recursive splitting by headers and paragraphs, and overlap windows all help ensure that retrieved chunks contain complete thoughts rather than arbitrary fragments. Some teams even use LLM-assisted chunking, where a model identifies logical section boundaries before embedding.
Hybrid Search
Combine vector similarity search with keyword-based (BM25) search. Vector search excels at semantic matching; keyword search excels at exact-match precision. Running both in parallel and merging results with a re-ranker produces more stable retrieval across phrasings of the same question.
Deterministic Retrieval Settings
If your vector database supports exact nearest-neighbor search (as opposed to approximate), use it for use cases where consistency matters more than latency. Set explicit result limits, disable randomized tie-breaking, and lock your embedding model version.
Query Expansion and Canonicalization
Before the query hits the retriever, normalize it. Strip filler words, expand abbreviations, and use a lightweight model to rewrite queries into a canonical form. This reduces the surface area of embedding instability — different phrasings map to the same (or more similar) query vectors.
These measures meaningfully reduce variance but do not eliminate it. The reason being structural: you're still operating on unstructured data, and the retrieval mechanism is still fundamentally probabilistic (can't avoid it).
Approach 2: Structured Output Constraints
Another angle is to constrain what the model can do with the retrieved context.
Schema-enforced generation. Force the model to return structured JSON conforming to a predefined schema rather than free-form text, removing stylistic and structural variance. The model can still select different facts, but the format of the answer is deterministic.
Citation-grounded answers. Require the model to include explicit citations (chunk IDs, page numbers) for every claim it makes. This doesn't prevent inconsistency, but it makes inconsistency visible — you can audit which chunks informed which answers and detect when the retriever is producing unstable results.
Consensus generation. Run the same query multiple times, generate several answers, and use an evaluation model to select or merge the most consistent response. Frameworks like RAGAS and Open-RAG-Eval formalize this with consistency-adjusted metrics. The tradeoff is latency and cost since you're multiplying inference calls.
These approaches treat symptoms intelligently. They're worth implementing. But they're still working within the constraint of an unstructured knowledge base that the retriever is trying to navigate probabilistically.
Approach 3: Structured Knowledge Layers — Ontologies and Knowledge Graphs
Here's the core insight: RAG inconsistency is fundamentally a retrieval problem, and retrieval is only as good as the structure of what's being retrieved.
When your knowledge base is a pile of unstructured text — PDFs, transcripts, support tickets, Slack threads — the retriever is performing a loose semantic search over fragments. It's asking: "which chunks feel most similar to this query?" That's a useful heuristic, but it's a heuristic. It has no understanding of what the data actually means, what entities are present, how they relate to each other, or what constitutes a complete answer.
Ontologies and knowledge graphs attack this problem at the root.
An ontology is a formal, structured representation of concepts and their relationships within a domain. Rather than storing raw text and hoping the embedding model captures meaning, an ontology explicitly defines: these are the entities in the data (people, products, issues, topics), these are the relationships between them (causes, mentions, correlates with), and these are the properties that can be quantified (sentiment, frequency, confidence, source).
A knowledge graph instantiates that ontology with real data. Instead of a vector database full of text chunks, you have a structured, queryable graph of facts — each tied back to source evidence.
When an AI agent queries a knowledge graph instead of (or in addition to) a vector store, the retrieval step is no longer a probabilistic search through semantic space. It's a structured traversal of explicit relationships. The same query returns the same subgraph every time, because the underlying data is organized, not approximated.
Research bears this out. A 2025 study comparing vector-based RAG, Microsoft's GraphRAG, and ontology-guided knowledge graphs found that ontology-guided approaches matched or exceeded the accuracy of state-of-the-art frameworks — reaching 90% accuracy compared to 60% for baseline vector RAG — while also providing full traceability from answer back to source.
Why This Matters for Consistency
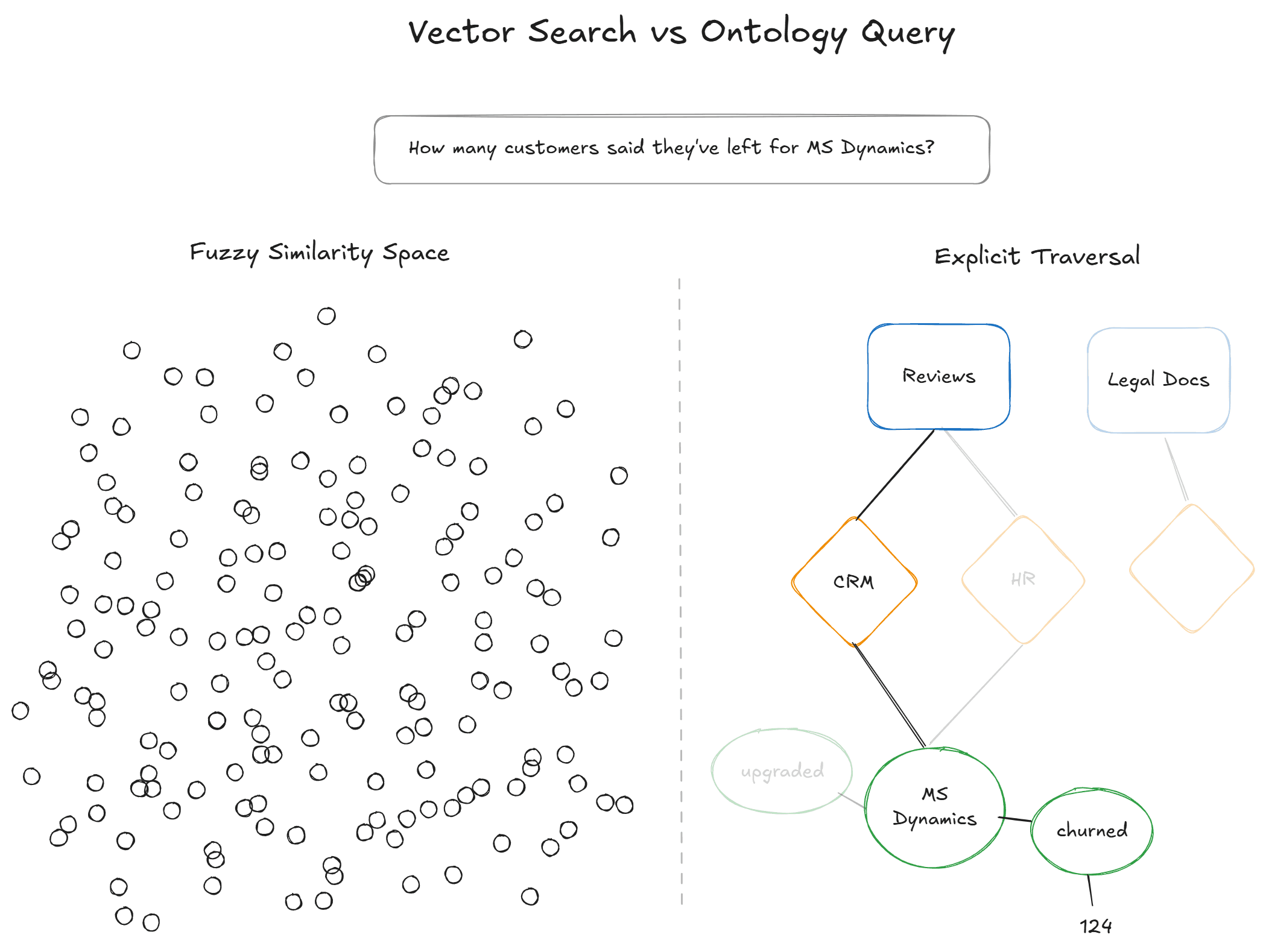
The consistency gains from structured knowledge come from several properties:
Deterministic retrieval. When the knowledge base is a graph of entities and relationships, the retrieval operation is a graph query — not a similarity search. The same query traverses the same edges and returns the same nodes. No need for approximate nearest neighbors, embedding variance, or chunking artifacts.
Quantified signals. Instead of asking a language model to infer that customer churn is trending upward from a bag of support tickets, a structured system can provide the exact count: 8,412 documents tagged with churn risk, up 24% from last period. The model reports a number as opposed to an impression.
Auditable provenance. Every fact in the response can be traced back to specific source documents through explicit links in the graph. Whereas most AI systems try and replicate this via a citation, having the quantified source data in the database already provides a verifiable chain of evidence.
Complete context. Ontologies define what a "complete answer" looks like for a given question type. If the question is about a specific entity, the graph can return all properties and relationships of that entity — not just the chunks that happened to be semantically closest.
The Tradeoff
Building and maintaining ontologies is nontrivial. Traditional knowledge engineering requires domain expertise, manual schema design, and ongoing curation. This is the historical bottleneck that kept ontology-based approaches limited to specialized domains like biomedicine and legal compliance.
But this tradeoff is shifting. Automated approaches to ontology construction — using LLMs to extract entities, relationships, and hierarchies from unstructured data, then organizing them into structured, queryable formats — are collapsing the build cost. What once took a team of knowledge engineers months can now be bootstrapped from raw data in hours or weeks.
The inductive approach (such as Siftree's Inductive Intelligence) is particularly promising: rather than defining categories top-down and forcing data into them, let the data define its own structure. Extract entities and facts from source documents. Discover clusters and patterns. Build the ontology bottom-up. This preserves the richness of the original data while imposing the structure needed for reliable retrieval.
Approach 4: Let AI Agents Query Structured Data Directly
There's a further evolution beyond "better retrieval": giving AI agents the ability to query structured data programmatically rather than relying on the retrieve-and-generate pattern at all.
The Model Context Protocol (MCP), now an open standard governed by the Linux Foundation and adopted by Anthropic, OpenAI, Google, and Microsoft, defines a universal interface for AI agents to connect to external data sources — databases, APIs, knowledge bases — and issue structured queries against them.
In a traditional RAG pipeline, the agent has no control over what it retrieves. It submits a query, receives whatever the retriever returns, and generates from that context. With an MCP-connected structured knowledge base, the agent can:
Query for a specific entity and retrieve all of its properties and relationships.
Filter by quantitative thresholds (e.g., "show me all topics with sentiment below -0.3 and frequency above 1,000").
Traverse relationships (e.g., "what entities are connected to this churn signal, and what source documents support that connection?").
Ask follow-up queries based on what it finds, navigating the knowledge graph iteratively rather than in a single blind retrieval step.
This fundamentally changes the reliability profile because the agent is no longer guessing at relevance through vector similarity and is now executing structured operations against a defined schema. The same query returns the same results, because the data is organized and the query is explicit.
For teams building agentic AI workflows — customer support automation, market intelligence, competitive analysis, regulatory monitoring — this represents a qualitative leap in reliability. The agent can explore data the way an analyst would: ask a question, inspect the results, drill deeper, and build a response grounded in specific, auditable evidence.
Choosing Your Approach
These approaches aren't mutually exclusive, but form a spectrum from quick wins to architectural transformation:
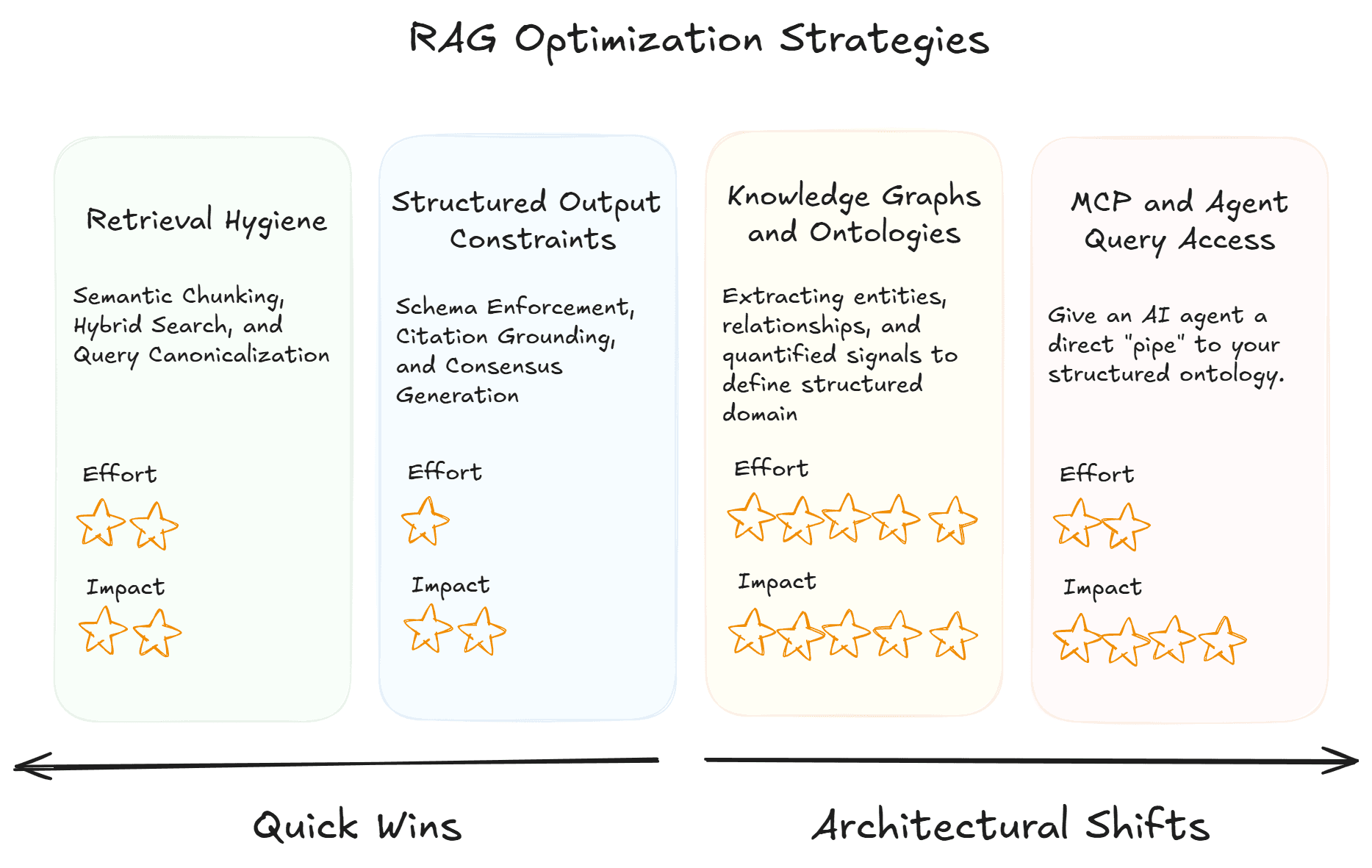
If you need immediate improvement: Tighten retrieval hygiene. Semantic chunking, hybrid search, query canonicalization, and deterministic retrieval settings will reduce variance meaningfully within your existing pipeline.
If you need auditable, consistent outputs for regulated or high-stakes use cases: Add structured output constraints. Schema enforcement, citation grounding, and consistency evaluation catch and surface variance even when it can't be fully eliminated.
If you're dealing with large-scale unstructured data and can't tolerate retrieval-layer variance: Move toward structured knowledge. Ontology-based approaches that extract entities, relationships, and quantified signals from your data — and organize them into queryable, auditable structures — eliminate the dominant source of inconsistency.
If you're building agentic systems that need to operate autonomously on data: Give agents structured query access via protocols like MCP. Replace the "retrieve and hope" pattern with explicit, repeatable data operations that an agent can execute, verify, and build on.
The consistent thread across all of these is a shift from unstructured retrieval to structured access. The more structure your data has, the less your system has to guess — and the less it guesses, the more consistent it becomes.
The Deeper Principle
RAG was a breakthrough because it showed that language models don't need to memorize everything — they can retrieve what they need at inference time. But the first generation of RAG assumed that vector similarity over raw text chunks would be sufficient for reliable retrieval. For many use cases, it's not.
The next generation of retrieval isn't about better embeddings or larger context windows, it's about giving the model something worth retrieving: data that's been understood, structured, quantified, and made explicitly queryable. Whether that structure comes from a hand-built ontology, an automated extraction pipeline, or a hybrid approach doesn't matter as much as the fact that it exists.
Consistency in AI isn't solely a prompt engineering problem, but a data architecture problem as well. Solve the architecture, and the consistency follows.



