
The Best Optimization Step for Unstructured Data Analytics
Tech

Every data team knows that ETL is the beginning of the story, not the end. You extract, transform, and load — and then the real work starts. You build normalized tables, design dimensional models, layer on semantic definitions, governed data marts, and materialized views tuned for the queries your business actually runs. The value isn't in getting data into storage. It's in how you organize it once it's there.
So why does the unstructured data world act like storage is the finish line?
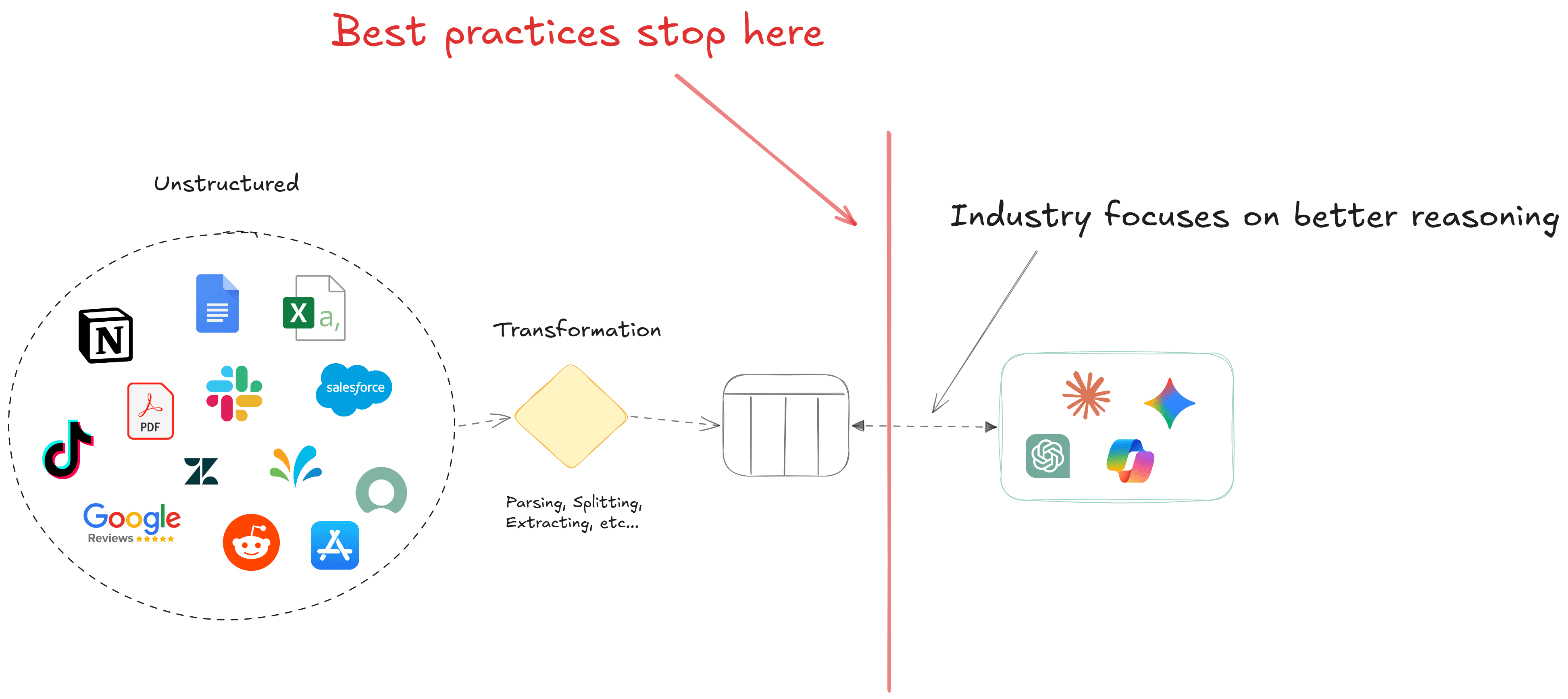
The Current Unstructured Pipeline: ETL and Nothing Else
When most companies build "context" for AI systems, the architecture looks roughly the same everywhere: ingest documents, parse them (OCR, layout detection, whatever the format demands), chunk the output, maybe extract some entities or run a classification pass, generate embeddings, and store everything in a vector database or graph. Done.
That's an ETL process. A good one, even. But it's only an ETL process — it stops at the first layer of storage. There's no modeling step, no semantic organization, no governed views, etc.
In the structured world, this would be like dumping CSV extracts into a database and pointing your BI tool at them. Nobody does that (anymore). We learned decades ago that the gap between "data in storage" and "data ready for analytics consumption" is where most of the value gets created.
Why This Matters: The Failure Modes Are Predictable
The consequences of stopping at storage show up the moment you try to ask anything beyond simple point lookups.
Consider a query like: "Summarize all compliance risks across our contract corpus." This is a thematic aggregation — you need the system to identify a concept (compliance risk) across thousands of documents, group the relevant passages, and synthesize a coherent answer. Vector similarity search doesn't serve this well. It retrieves individual chunks that are semantically close to the query embedding, but it has no concept of coverage across a corpus, no way to ensure you've surfaced all relevant instances, and no mechanism for organizing what it finds into a structure that supports reliable aggregation.
The model is left doing the heavy lifting: reasoning over a pile of retrieved chunks, hoping the retrieval was comprehensive, trying to quantify and categorize on the fly. The result is probabilistic where it should be deterministic. You get different answers on different runs. You can't audit how the aggregation was performed. And the business learns, correctly, that it can't trust the output for anything that matters.
The "Better Embeddings" Trap
The instinct is to solve this with better representations — a more capable embedding model, a more sophisticated chunking strategy, hybrid search with BM25, reranking, or DocETL. And these help at the margins. But they're optimizing the wrong layer. They improve retrieval of individual chunks, which is the ETL-equivalent concern: getting the right raw material into the pipeline.
What they don't address is the absence of any organizing structure between storage and consumption. No matter how good your embeddings are, you still don't have dimensional models, semantic groupings, or pre-aggregated views. You're still handing a model a bag of chunks and asking it to be the entire analytical layer.
In the structured world, we had this debate long ago. Kimball argued for dimensional models organized around business processes whereas Inmon argued for normalized enterprise data warehouses. They disagreed on the approach, but neither of them suggested skipping the modeling step entirely and pointing reports at raw tables (that would have been absurd), and yet that's exactly what we do with unstructured data today.
What the Best Step Looks Like
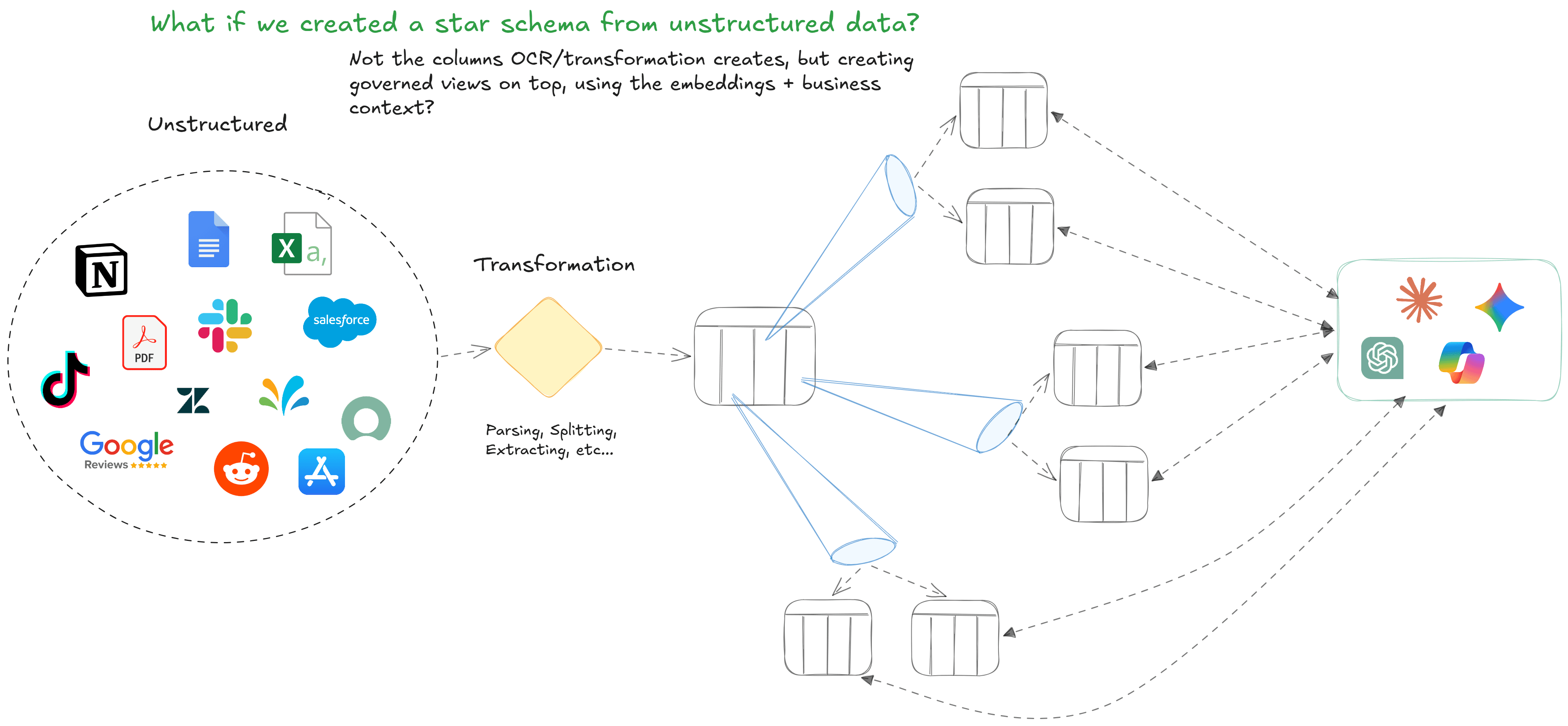
The missing piece is a modeling layer for unstructured data — something analogous to what dimensional modeling did for structured analytics. Not just "documents stored with embeddings," but documents organized by what they contain and by how the business thinks about them.
This means using embedding density and domain knowledge to derive intentional groupings: clusters that reflect actual business concepts, not just vector proximity. It means building governed views on top of those groupings — pre-aggregated, permissioned, and semantically defined — so that downstream consumers (models or humans) interact with organized knowledge rather than raw corpus.
Think of it as a star schema for unstructured data. Your fact table is the document content and your dimensions are the business concepts those documents relate to: risk categories, product lines, customer segments, regulatory domains. And your views are pre-built aggregations that answer the thematic queries your organization actually asks, deterministically, without requiring a model to perform ad-hoc reasoning over thousands of chunks.
At Siftree, we use embeddings combined with business context to construct these governed views on top of transformed unstructured data. The structured outputs that OCR and LLMs produce aren't the endpoint — they're the input to a modeling layer that creates dimensional structure derived from embedding density and domain knowledge. The result is pre-aggregated, governed, and auditable.
The Industry Will Get Here Eventually
Structured data took the same journey. We went from flat files to relational databases to dimensional models to semantic layers to governed data products. Each step added organizational intelligence between raw data and consumption. Each step made the outputs more reliable, more auditable, and more aligned with how the business actually thinks.
Unstructured data is still at step two. We've built good pipelines for getting documents into storage. We haven't built the layers that make that storage useful for anything beyond simple retrieval. And we've been papering over the gap by asking increasingly capable models to reason their way through it.
That works for point queries. It doesn't work for aggregation, governance, or any use case where the business needs deterministic, auditable outputs. The modeling layer isn't optional — most just haven't built it yet.



