
What Is an MCP Server? The Protocol Powering AI Agents
Tech

MCP is a protocol that lets any agent connect to any data source, with a consistent interface and no bespoke integration overhead, acting as foundational infrastructure for AI enablement.
Agents Have a Context Problem
AI agents are getting remarkably capable. They can reason, plan, write code, and run multi-step workflows with minimal intervention. But there's a persistent gap between what an agent can think and what it actually knows at the moment you need it to act.
Language models are trained on static snapshots of the world. When you deploy one, its knowledge is frozen. It doesn't know what's in your database. It doesn't know today's customer sentiment on social media. It doesn't know what just happened in a Slack channel five minutes ago. Without external context, even the most sophisticated model is, in practical terms, flying blind.
This is the gap that MCP — the Model Context Protocol — was built to close.
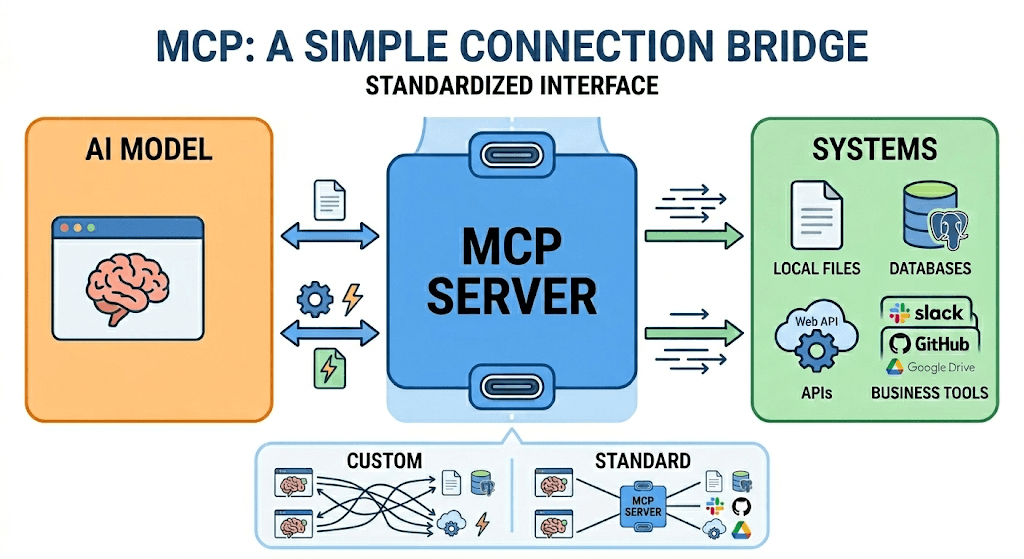
Why Not Just Use an API?
To understand why MCP matters, it helps to understand what an API is and where it falls short for agents.
An API (Application Programming Interface) is a defined contract between two pieces of software. You send a request in a specific format; the server returns a response in a specific format. APIs are the backbone of the modern internet — they're how your weather app talks to a weather service, how Stripe processes a payment, how Twitter serves a timeline.
For human-driven software, APIs are perfect. A developer writes deterministic code that knows exactly which endpoint to call, with exactly which parameters, under exactly which conditions.
But AI agents don't work that way. They're probabilistic, context-dependent, and dynamic. An agent shouldn't need to know ahead of time which exact API call to make — it should be able to discover what tools are available and reason about how to use them.
Here's the tension: every API is its own bespoke interface. For an agent to use ten different data sources, a developer has to write ten different integration layers, handle ten different authentication schemes, and teach the agent ten different request formats. This doesn't scale. It's brittle. And it fundamentally keeps agents dependent on human-written plumbing rather than genuine autonomy.
MCP solves this by standardizing the interface. It's a protocol — not a product — that defines a universal way for AI models to connect to external data sources and tools. Think of it as USB-C for AI: one standard port, any device. An agent that speaks MCP can connect to any MCP-compatible server without bespoke integration work.
Anthropic introduced MCP in late 2024. The core idea is elegant: instead of integrating every tool separately into every model, you build the tool as an MCP server once — and every MCP-compatible agent can use it immediately.
How Does an MCP Server Actually Work?
At its core, an MCP server is a lightweight process that wraps a data source or tool and exposes it through a standardized interface. The flow has three actors: the host (the AI application, like Claude or Cursor), the client (the MCP layer built into that host), and the server (the external resource you're connecting to).
When an agent starts a task, the MCP client sends a discovery request to the server asking: what can you do? The server responds with a list of available tools and resources — their names, descriptions, and input schemas. The agent reads this manifest and decides which tools are relevant to the task at hand. It then calls those tools directly, passing structured inputs and receiving structured outputs back into its context window.
The whole exchange is stateless and JSON-based, running over standard transport protocols (stdio locally, HTTP remotely). There's no proprietary SDK to install, no vendor lock-in, no training required to add a new server. From the agent's perspective, every MCP server looks the same — which is exactly the point.
This architecture means the intelligence stays in the model and the data stays in the server. The MCP layer is just the handshake between them.
The Real Benefits
The benefits of MCP extend beyond developer convenience. They represent a meaningful architectural shift in how AI systems access the world.
Dynamic tool discovery. An MCP-compatible agent can query an MCP server at runtime to discover what capabilities it exposes. No hardcoded tool lists. No brittle configuration files. The agent reasons about what's available and decides how to use it.
Real-time, contextual data. APIs can deliver current data, but MCP makes that data accessible in a way that's natively composable with an agent's reasoning loop. The agent isn't just fetching data — it's integrating live context into its decision-making mid-task.
Composability. Because every MCP server speaks the same protocol, agents can combine multiple servers fluidly. A single agent workflow can pull from a CRM, a social media intelligence platform, a code repository, and a calendar — all without custom glue code between them.
Reduced hallucination surface. When an agent is grounded in real, structured, queryable data rather than relying on parametric memory from training, it's less likely to confabulate. The facts come from the data, not the model's best guess.
Ecosystem network effects. A standard protocol means the MCP server ecosystem compounds in value. Every new server built to the standard becomes immediately useful to every MCP-compatible agent. The ecosystem grows faster than any single vendor could maintain alone.
Early Adopters and the Tonal Shift in the Industry
MCP's adoption curve has been steep — and the companies that moved early sent a clear signal to the rest of the industry: this is the interface layer for agentic AI.
Anthropic introduced the protocol in November 2024 and open-sourced it, establishing MCP as a neutral standard rather than proprietary infrastructure for the rest of the industry.
Block (Square) was one of the first enterprise adopters, integrating MCP into internal tooling to give AI agents access to financial workflows and internal systems.
Replit embedded MCP into its AI coding environment, giving agents direct access to the file system, packages, and execution context — making code generation dramatically more reliable.
Sourcegraph (Cody) adopted MCP to give its AI coding assistant access to live codebase context, moving beyond static RAG toward dynamic, real-time code understanding.
Zed integrated MCP to expose project context to its AI features, setting an example for the entire IDE category.
OpenAI announced support for MCP in its agent infrastructure in early 2025 — a landmark moment that effectively ratified the protocol as an industry standard rather than an Anthropic experiment.
The pattern across these early adopters is consistent: organizations operating at the frontier of AI capability recognized that getting data to the model, not just making the model smarter, was the critical bottleneck. MCP gave them a principled way to solve it.
By mid-2025, the conversation had shifted from "should we adopt MCP?" to "what MCP servers are you building?" The protocol moved from interesting experiment to baseline infrastructure in under a year.
MCP vs RAG — What's the Difference?
These two terms get conflated constantly, but they solve different problems at different layers.
RAG (Retrieval-Augmented Generation) is a technique for grounding a model's responses by fetching relevant documents from a vector database and stuffing them into the prompt before generation. It's powerful, but it's fundamentally a pre-generation step — you retrieve context, then generate. The model is still passive; it receives whatever the retrieval pipeline hands it.
MCP operates at the agentic layer. Rather than pre-loading context before a generation call, MCP lets the agent actively decide — mid-task — what data it needs, query for it, and incorporate the result into its next reasoning step. The agent is a participant in the data retrieval process, not just a consumer of it.
In practice, they're complementary. A well-architected agent might use RAG to load relevant background documents at the start of a session, then use MCP to query live data sources dynamically as the task evolves. RAG provides the library; MCP provides the ability to pick up the phone and call someone in real time.
The key distinction: RAG is a pipeline pattern. MCP is a protocol. One is a technique you implement; the other is a standard you adopt.
How to Get Started with MCP
Getting an agent connected to an MCP server is simpler than it sounds. The ecosystem has matured quickly, and most major agent frameworks now have native MCP support.
If you're using Claude: Anthropic's Claude desktop app and API both support MCP natively. You configure MCP servers in a claude_desktop_config.json file, pointing to either a local server process or a remote URL. From there, Claude discovers available tools automatically on each session start.
If you're using Cursor or another IDE agent: Most leading AI coding environments have added MCP support in their settings. You specify the server endpoint, and the agent gains access to whatever that server exposes — file systems, databases, APIs, or data platforms.
If you're building your own agent: Anthropic publishes open-source SDKs for MCP in Python and TypeScript. You can stand up a basic MCP server in under fifty lines of code. The harder problem — and the more valuable one — is what you put behind the server.
That's where purpose-built MCP servers like Siftree come in.
Siftree: MCP for Social Media Intelligence
Among the most compelling applications of MCP is grounding agents in real-time social media data — and this is precisely the problem Siftree was built to solve.
Social media is where culture moves. It's where brand narratives form, consumer sentiment shifts, and trends emerge before they reach any traditional data source. But raw social data is noisy, unstructured, and massive in volume. For an AI agent, querying raw social feeds is worse than useless — it floods the context window with noise and produces outputs that are unverifiable and non-reproducible.
Siftree ingests TikTok, Reddit, YouTube, Instagram, and more — processes every post through its intelligence pipeline, then serves the output as a structured, queryable MCP server. Agents connect to Siftree the same way they'd connect to any MCP tool, and immediately gain access to millions of enriched social data points.
The key distinction is Siftree's governed ontology: a structured vocabulary that maps messy social language to consistent, queryable concepts. "Churn Risk," for example, maps to the same 2,341 documents whether the agent querying is Claude, ChatGPT, or a custom model. Different runs produce the same answers — because the consistency lives in the data layer, not the model.
Every post is processed before it reaches your agent — embedded for neural search, scored for sentiment, tagged with named entities, and grouped into topic clusters. Agents query by meaning, not keywords. And every insight traces back to the exact source with quantified citations. The output is auditable by design.
Siftree also identifies emerging narratives before they reach mainstream visibility — spotting niche conversations in sub-cultures months before they become vertical spikes. For agents running competitive intelligence, brand monitoring, or market research workflows, this is the difference between reacting to trends and anticipating them.
The Infrastructure Layer AI Actually Needed
The last few years of AI progress have been dominated by a single question: how smart can we make the model? MCP represents a maturation of that conversation — a recognition that intelligence alone isn't sufficient. What agents need is grounding.
A protocol that lets any agent connect to any data source, with a consistent interface and no bespoke integration overhead, is foundational infrastructure. The fact that it went from proposal to industry-wide adoption in under eighteen months tells you something about how acutely that gap was felt.
We're now in a world where the question isn't just "which model should I use?" but "which MCP servers should my agent have access to?" The answer to the second question often determines how useful the first one actually is.
For teams building agents that need to reason about what the world thinks, what customers feel, and what conversations are happening right now — that question has a clear answer.




