Inductive Intelligence
Inductive Intelligence
Inductive Intelligence
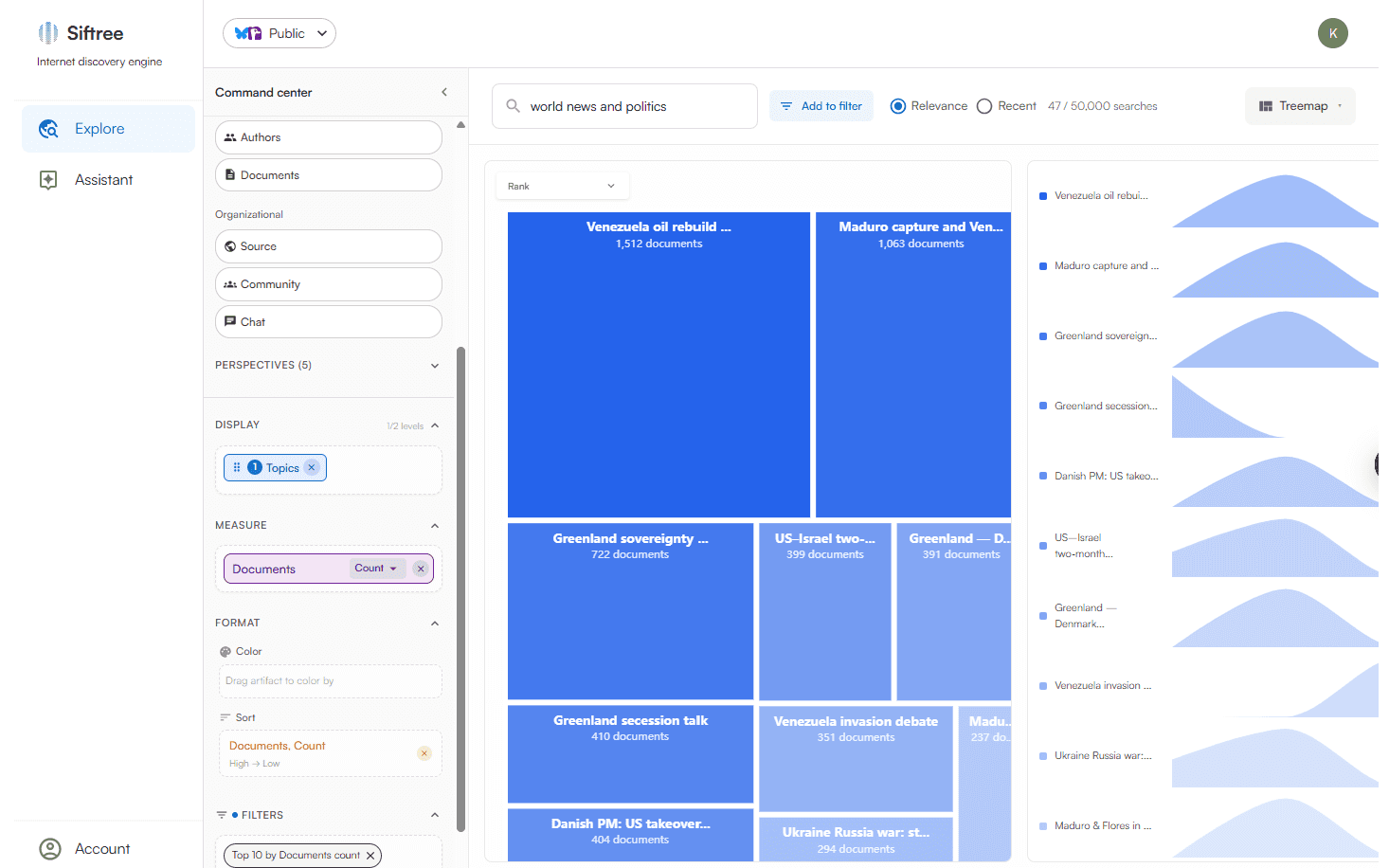
Inductive Intelligence is the inverse of the traditional ETL process. Instead of defining the schema before the data is loaded, Siftree recursively atomizes the data into learned artifacts, letting the data generate its own schema without human intervention.
Intelligence derived from emergence, not queries.
Inductive Intelligence is the inverse of the traditional ETL process. Instead of defining the schema before the data is loaded, Siftree recursively atomizes the data into learned artifacts, letting the data generate its own schema without human intervention.
Intelligence derived from emergence, not queries.
Inductive Intelligence is the inverse of the traditional ETL process. Instead of defining the schema before the data is loaded, Siftree recursively atomizes the data into learned artifacts, letting the data generate its own schema without human intervention.
Intelligence derived from emergence, not queries.

90% of data is unused because it is unstructured; we change that.
90% of data is unused because it is unstructured; we change that.
90% of data is unused because it is unstructured; we change that.
90% of data is unused because it is unstructured; we change that.
Dimensional Rigidity
Traditional business intelligence platforms force organizations to choose between quantitative aggregation (which ignores the nuance of text) or qualitative synthesis (which lacks statistical significance).

Dimensional Rigidity
Traditional business intelligence platforms force organizations to choose between quantitative aggregation (which ignores the nuance of text) or qualitative synthesis (which lacks statistical significance).
Dimensional Rigidity
Traditional business intelligence platforms force organizations to choose between quantitative aggregation (which ignores the nuance of text) or qualitative synthesis (which lacks statistical significance).
Dimensional Rigidity
Traditional business intelligence platforms force organizations to choose between quantitative aggregation (which ignores the nuance of text) or qualitative synthesis (which lacks statistical significance).
Dimensional Rigidity
Traditional business intelligence platforms force organizations to choose between quantitative aggregation (which ignores the nuance of text) or qualitative synthesis (which lacks statistical significance).
Generative AI was supposed to solve this
While these tools excel at Semantic Retrieval (finding, reading documents) and Summarization (condensing, synthesizing information), they have largely failed at Semantic Aggregation because they lack a structured schema.

Generative AI was supposed to solve this
While these tools excel at Semantic Retrieval (finding, reading documents) and Summarization (condensing, synthesizing information), they have largely failed at Semantic Aggregation because they lack a structured schema.
Generative AI was supposed to solve this
While these tools excel at Semantic Retrieval (finding, reading documents) and Summarization (condensing, synthesizing information), they have largely failed at Semantic Aggregation because they lack a structured schema.
Generative AI was supposed to solve this
While these tools excel at Semantic Retrieval (finding, reading documents) and Summarization (condensing, synthesizing information), they have largely failed at Semantic Aggregation because they lack a structured schema.
We turn depth into dimensions
Automated schema induction solves this problem. Once our model transforms the data into a high-dimensional vector space, it functions exactly like columns in a database, enabling you to pivot layers of unstructured data against structured metadata.

We turn depth into dimensions
Automated schema induction solves this problem. Once our model transforms the data into a high-dimensional vector space, it functions exactly like columns in a database, enabling you to pivot layers of unstructured data against structured metadata.
We turn depth into dimensions
Automated schema induction solves this problem. Once our model transforms the data into a high-dimensional vector space, it functions exactly like columns in a database, enabling you to pivot layers of unstructured data against structured metadata.
We turn depth into dimensions
Automated schema induction solves this problem. Once our model transforms the data into a high-dimensional vector space, it functions exactly like columns in a database, enabling you to pivot layers of unstructured data against structured metadata.
The result?
You can slice, dice, and break down unstructured data like never before. We take care of all the messy work for you, and organize your data into a hierarchical taxonomy that's ready to use right away. And because your data is embedded, you're able to comb through it with neural search, sifting through your data like a knife through butter.